

研究方法
外部反饋的應用:不依賴模型自我生成的反饋,研究者使用外部反饋來指導LLM改進翻譯。
開放模型的使用:研究中使用了開源的LLaMA-2模型,而不是像GPT-3.5或PaLM-2等這樣的閉源模型。
并且研究者考慮到了兩種指導語言模型編輯機器翻譯錯誤注釋的策略:提示和用指令微調。首先,他們使用不同形式的反饋,以不同的粒度提示LLaMA-2模型。

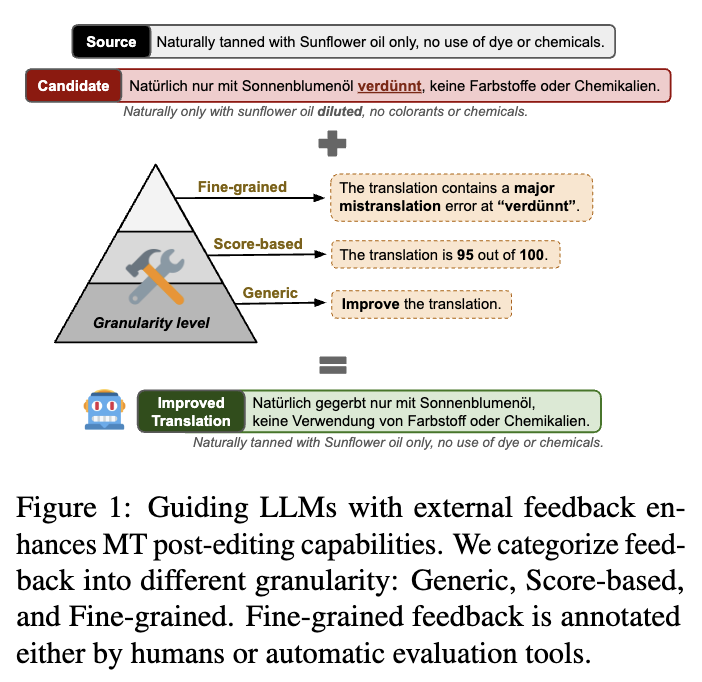
研究采用了三種反饋形式:
一般性反饋:不提供具體細節,沒有具體指令,只是提示模型改進初始翻譯。
基于評分的反饋:提供一個從0到100的單一MQM評分,反映初始翻譯的總體質量。
細粒度反饋:提供具體且詳細的錯誤注釋,可能包括錯誤范圍、錯誤類型和嚴重程度。這種反饋可以由人工或者自動注釋工具進行。
研究發現
在中英、英德和英俄三個語言對上,研究發現使用反饋提示LLM進行翻譯編輯可以持續提高機器翻譯和譯后編輯質量。盡管細粒度反饋在改進輸出方面作用有限,但接下來他們用細粒度的錯誤注釋對LLaMA-2模型進行了微調,研究者發現微調帶來了“額外的性能提升”。不僅如此,細調后的模型不僅能修復特定錯誤,還能增強目標語言的自然性。

未來展望
通過這些結果,研究者發現:編輯后的MT輸出不需要最大的專有LLM模型,可以用較小的開源模型來完成。他們計劃進一步探索如何創建一個可以自動評估任何MT輸入的工作流程,并決定是否有必要進行后期編輯以及如何進行后期編輯,以及確定使用最合適的反饋機制。此外,他們還希望進一步探索如何最大限度地減少對人工注釋的依賴,因為“大規模獲取人工注釋的成本很高”。

研究者計劃進一步探索創建一個自動評估MT輸入并決定是否需要后編輯的工作流程,同時尋找最合適的反饋機制以盡可能減少對人工注釋的依賴。
